3.1 Hadoop简介
Hadoop是什么?
Apache Hadoop是一个软件框架,可以在具有数千个节点和PB级数据的大型集群上进行分布式处理。Apache Hadoop集群可以使用故障率一般较高的低价通用硬件来构建。Hadoop的设计能够在没有用户干预的情况下优雅地处理这些故障。此外,Hadoop采用了让计算贴近数据(move computation to the data)的方法,从而显著降低了网络流量。它的用户能够快速开发并行的应用程序,从而专注于业务逻辑,而无需承担分发数据、分发用于并行处理的代码以及处理故障等繁重的工作。Apache Hadoop主要包含四个项目:Hadoop Common、Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)、YARN(Yet Another Resource Negotiator)和MapReduce。
简而言之,HDFS用于存储数据,MapReduce用于处理数据,YARN则用来管理集群的资源(CPU和内存)及支持Hadoop的公共实用程序。Apache Hadoop可以与许多其他项目集成,如Avro、Hive、Pig、HBase、Zookeeper和Apache Spark。
Hadoop带来的主要是以下三个组件:
- 可靠的分布式数据存储框架:HDFS
- 用于并行处理数据的框架:MapReduce、Crunch、Cascading、Hive、Tez、Impala、Pig、Mahout、Spark和Giraph
- 用于集群资源管理的框架:YARN和Slider
Hadoop就是一个分布式计算的解决方案。
Hadoop能做什么?
hadoop擅长日志分析,facebook就用Hive来进行日志分析,2009年时facebook就有非编程人员的30%的人使用HiveQL进行数据分析;淘宝搜索中的自定义筛选也使用的Hive;利用Pig还可以做高级的数据处理,包括Twitter、LinkedIn上用于发现您可能认识的人,可以实现类似Amazon.com的协同过滤的推荐效果。淘宝的商品推荐也是!在Yahoo!的40%的Hadoop作业是用pig运行的,包括垃圾邮件的识别和过滤,还有用户特征建模。(2012年8月25新更新,天猫的推荐系统是hive,少量尝试mahout!)
从现在企业的使用趋势来看,Pig慢慢有点从企业的视野中淡化了.+
Hadoop的版本演进
当前Hadoop有两大版本:Hadoop 1.0和Hadoop 2.0,如下图所示。
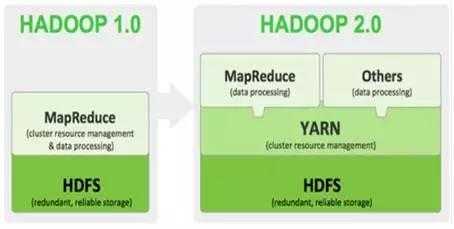
Hadoop版本演进图+
Hadoop1.0被称为第一代Hadoop,由分布式文件系统HDFS和分布式计算框架MapReduce组成,其中,HDFS由一个NameNode和多个DataNode组成,MapReduce由一个JobTracker和多个TaskTracker组成,对应Hadoop版本为0.20.x、0.21.X,0.22.x和Hadoop 1.x。其中0.20.x是比较稳定的版本,最后演化为1. x,变成稳定版本。0.21.x和0.22.x则增加了NameNode HA等新特性。
第二代Hadoop被称为Hadoop2.0,是为克服Hadoop 1.0中HDFS和MapReduce存在的各种问题而提出的,对应Hadoop版本为Hadoop 0.23.x和2.x。
针对Hadoop1.0中NameNode HA不支持自动切换且切换时间过长的风险,Hadoop2.0提出了基于共享存储的HA方式,支持失败自动切换切回。
针对Hadoop 1.0中的单NameNode制约HDFS的扩展性问题,提出了HDFS Federation机制,它允许多个NameNode各自分管不同的命名空间进而实现数据访问隔离和集群横向扩展。
针对Hadoop 1.0中的MapReduce在扩展性和多框架支持方面的不足,提出了全新的资源管理框架YARN,它将JobTracker中的资源管理和作业控制功能分开,分别由组件ResourceManager和ApplicationMaster实现。其中,ResourceManager负责所有应用程序的资源分配,而ApplicationMaster仅负责管理一个应用程序。相比于 Hadoop 1.0,Hadoop 2.0框架具有更好的扩展性、可用性、可靠性、向后兼容性和更高的资源利用率以及能支持除了MapReduce计算框架外的更多的计算框架,Hadoop 2.0目前是业界主流使用的Hadoop版本。