5.9 桶表(bucket)
桶表和分区表有类似的地方,都是将数据文件划分到不同的地方存储。不同的是,分区表是由用户指定数据处处的位置。而桶表是根据数据表的某个字段去hash值,然后模桶的数量,最终放到其中一个桶中,但是最终放到哪一个桶中,用户是不知道的。
创建桶表
create table bucket_table(id string) clustered by(id) into 4 buckets;
往桶表中加载数据
往桶表中加载数据不能再使用LOAD DATA 的方式,要采取以下的方式:
set hive.enforce.bucketing = true;
#有可能花些时间
insert into table bucket_table select name from multi_clumns_table;
insert overwrite table bucket_table select name from stu;
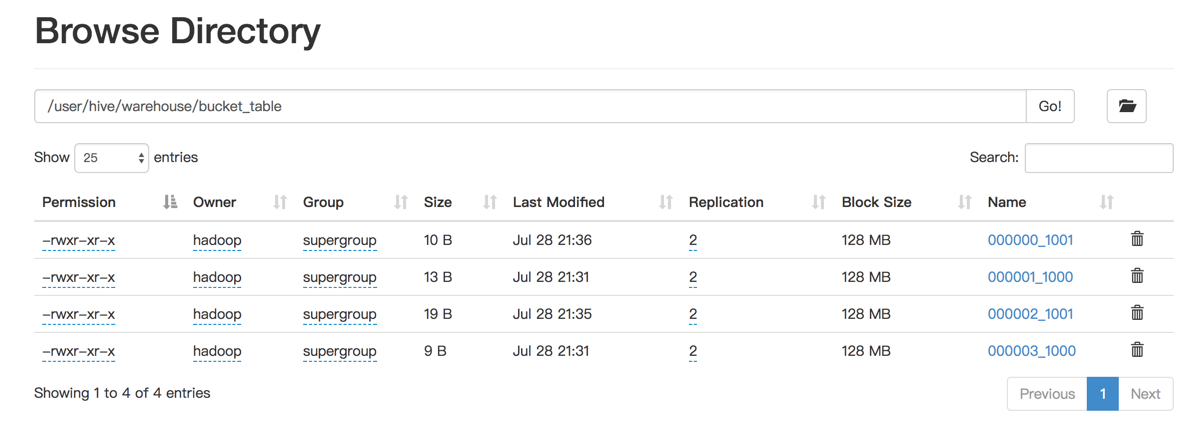
在HDFS的查看文件,如命令行所示,创建了4个bucket。
抽样检查
#抽样检查
select * from bucket_table tablesample(bucket 1 out of 4 on id);
tablesample是抽样语句,语法:TABLESAMPLE(BUCKET x OUT OF y)
y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。例如,table总共分了64份,当y=32时,抽取 (64/32=)2个bucket的数据,当y=128时,抽取(64/128=)1/2个bucket的数据。x表示从哪个bucket开始抽取。例 如,table总bucket数为32,tablesample(bucket 3 out of 16),表示总共抽取(32/16=)2个bucket的数据,分别为第3个bucket和第(3+16=)19个bucket的数据