7.1 Spark 集群安装和配置
Spark的集群架构图
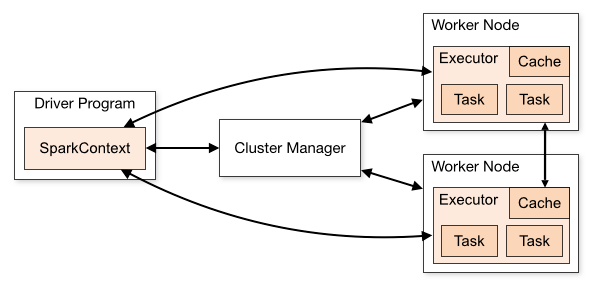
- Driver Program就是程序员所设计的Spark程序,在Spark程序中必须定义SparkContext,它是开发Spark应用程序的入口。
- SparkContext通过Cluster Manager管理整个集群,集群中包含多个worker Node,在每个worker node上都有Executor负责执行任务。
本文的Spark安装基于YARN安装。
安装环境:
虚拟机: VMWare Fusion 8.5.7
操作系统: RedHat Linux Server 7.2
JDK环境: JDK-8u131-linux-x64 Hadoop+YARN: Apache Hadoop 2.8
scala-2.10.6 Spark: spark-2.2.0
安装规划:
| 服务器名称 | 服务器IP | 备注 |
|---|---|---|
| hadoopmaster | 192.168.44.131 | Spark master |
| hadoopslave1 | 192.168.44.132 | Spark Work1 |
| hadoopslave2 | 192.168.44.133 | Spark Work2 |
安装步骤:
- 操作系统准备
- 安装和配置Hadoop和YARN
- 安装Scala
- 安装和配置Spark
安装过程:
由于操作系统、Hadoop、YARN已经在之前的文档的安装过了,本节不做叙述了
安装Scala
下载scala安装包
tar -zxvf scala-2.10.6.tgz
#配置环境变量
export SCALA_HOME=/usr/share/scala
export PATH=$SCALA_HOME/bin:$PATH
需要在所有的slave节点上安装scala。
安装Spark
下载Spark安装包
tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz
chmod -R 775 /hadoop/spark-2.2.0-bin-hadoop2.7
chown -R hadoop:hadoop /hadoop/spark-2.2.0-bin-hadoop2.7
#修改环境变量
export SPARK_HOME=/hadoop/spark-2.2.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
#进入spark配置目录
cd conf
cp spark-env.sh.template spark-env.sh #从配置模板复制
vi spark-env.sh #添加配置内容
export JAVA_HOME=/home/jdk1.8.0_131
export SCALA_HOME=/home/scala-2.10.6
export HADOOP_HOME=/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=/hadoop/hadoop-2.8.0/etc/hadoop
export SPARK_WORKER_MEMORY=500m
export SPARK_WORKER_CORES=1
export SPARK_EXECUTOR_MEMORY=500M
注:在设置Worker进程的CPU个数和内存大小,要注意机器的实际硬件条件,如果配置的超过当前Worker节点的硬件条件,Worker进程会启动失败。
#配置slave
cp slaves.template slaves
vi slaves
#设置slave节点
hadoopslave1
hadoopslave2
接着,将文件分发到slave服务器吧。
scp -r ./spark-2.2.0-bin-hadoop2.7 hadoopslave1:/hadoop/
scp -r ./spark-2.2.0-bin-hadoop2.7 hadoopslave2:/hadoop/
启动spark
sbin/start-all.sh
验证spark是否启动成功
用jps检查,在 master 上应该有以下几个进程:
$ jps
7949 Jps
7328 SecondaryNameNode
7805 Master
7137 NameNode
7475 ResourceManager
在 slave 上应该有以下几个进程:
$jps
3132 DataNode
3759 Worker
3858 Jps
3231 NodeManager
当然也可以进入进入Spark的Web管理页面: http://hadoopmaster:8080
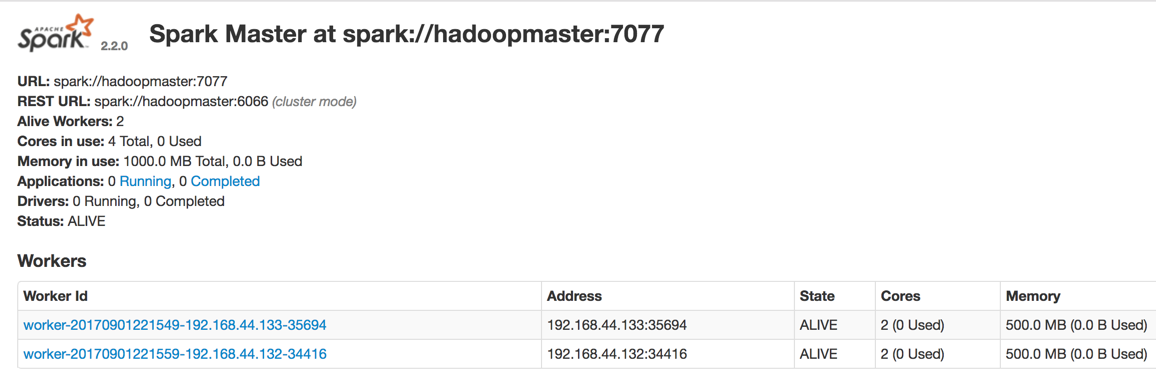
运行示例
Spark Standalone 集群模式运行
./spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoopmaster:7077 /hadoop/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar 100