3.2 Hadoop 完全分布式的搭建
Hadoop的安装过程如下:
- 安装JDK。Hadoop是基于Java开发的,所以首先必须安装JDK
- 设置SSH无密码登陆。Hadoop必须通过SSH和本地计算机以及其他主机连接,所以必须设置SSH。
- 下载和安装Hadoop。
- 设置hadoop环境变量。环境变量能够让我们更方便的使用hadoop的命令。
- Hadoop配置文件设置。Hadoop的配置文件来启用基本配置或者更高级的功能。
- 创建并格式化HDFS目录。HDFS目录是存储HDFS文件的地方,再启动hadoop之前必须先创建并格式化HDFS目录。
- 启动Hadoop。jps可以查看启动的组件。
- 测试Hadoop web界面。Hadoop界面可以查看当前Hadoop的状态: Node的节点、应用程序、任务运行状态等等。
3.2.1 系统环境
- VMWare Fusion 8.5.7
- RedHat Linux Server 7.2
- JDK-8u131-linux-x64
- Apache Hadoop 2.8
3.2.2 网络环境
- hadoopmaster 192.168.1.159
- hadoopslave1 192.168.1.76
- hadoopslave2 192.168.1.166
3.2.3 RedHat Linux Server 7.2 安装和准备
使用VMWare Fusion安装虚拟机,使用最小安装。安装完毕后拷贝2份副本。
| 名称 | 配置信息 | IP | 备注 |
|---|---|---|---|
| hadoopmaster | 1C/1G/30G | 192.168.44.131 | |
| hadoopslave1 | 1C/1G/30G | 192.168.44.132 | |
| hadoopslave2 | 1C/1G.30G | 192.168.44.133 |
备注:由于使用MacBook Pro搭建环境,因此配置信息都不是太大,大家在学习中可以根据自身情况调整。
3.2.4 Linux 7.2 服务器配置
由于使用了最小安装,因此需要进行以下设置:
YUM源配置
#首先删除自带的yum
rpm -aq|grep yum|xargs rpm -e --nodeps
#从阿里云下载yum相关安装包
wget http://mirrors.aliyun.com/centos/7.2.1511/os/x86_64/Packages/yum-metadata-parser-1.1.4-10.el7.x86_64.rpm
网络设置
vi /etc/sysconfig/network-scripts/ifcfg-enoXXXX
设置ONBOOT=yes
执行
service network restart
然后使用 ip addr show查看服务器IP信息。
Redhat 7.2不推荐使用ifconfig命令,也建议使用ip命令来查看和设置网络信息
关闭防火墙
systemctl stop firewalld #临时关闭
systemctl disable firewalld #永久关闭
设置hostname
为了方便后续操作,设置服务器名称
hostname hadoopmaster
以上命令修改会立即生效,但是重启后就会失效,使用以下命令修改:
hostnamectl set-hostname hadoopmaster
资源限制配置
此步骤要求在hadoopmaster hadoopslave1 hadoopslave2都要进行配置,以防止处理达到机器文件上限
- 通过修改/etc/security/limits.conf追击参数进行配置
HBASE和其他的数据库软件一样会同时打开很多文件,Linux默认的ulimit值是1024,这对HBASE来说太小了,当使用诸如bulkload这种工具导入数据的时候会得到这样的异常信息:java.io.IOException:Too many open files.我们需要改变这个值.这是对操作系统的操作,而不是通过HBASE配置文件完成的,我们可以大致估算ulimit值需要配置为多大,例如:每个列族至少有一个存储文件(HFile),每个被加载的Region可能管理多达5或6个列族所对应的存储文件,用于存储文件个数乘于列族数再乘以每个RegionServer中的RegIon数量得到RegionServer主机管理的存储文件数量.假如每个Region有3个列族,每个列族平均有3个存储文件,每个RegionServer有100个region,将至少需要3*3*100=900个文件.这些存储文件会被客户端大量的操作,涉及大量的磁盘操作.
vi /etc/security/limits.conf
在文件中添加如下内容:
hadoop - nofile 65535
hadoop - nproc 32000
可以使用ulimit -aH查看是否生效。
配置yum源
#将光盘mount到linux
mount /dev/cdrom /mnt
#移除以前的yum源
rm -rf /etc/yum.repos.d/*
#新建yum源
vi /etc/yum.repos.d/rhel7.repo
#内容
[rhel7-yum]
name=rhel7-source
baseurl=file:///mnt
enabled=1
gpgcheck=0
保存后,执行yum list,测试。
时间同步
由于集群之间需要时间同步,如下配置:
#安装chrony
yum install chrony
#启动服务
systemctl start chronyd.service
#查看时间同步信息
chronyc sources -v
#另外如果需要自定义时钟服务器,需要编辑配置文件
vi /etc/chrony.conf
server 0.rhel.pool.ntp.org iburst
server 1.rhel.pool.ntp.org iburst
server 192.168.44.131 iburst
#重启时间同步服务:#
systemctl restart chronyd.service
#查看时间同步状态:#
systemctl status chronyd.service
关闭SELinux
#查看SELinux状态
sestatus
#临时关闭
setenforce 0
#彻底关闭
vi /etc/sysconfig/selinux
SELINUX=disabled
3.2.5 JDK安装和配置
首先解压jdktar xvfz jdk-8u131-linux-x64.tar.gz
设置JAVA环境变量
vi /etc/profile
export JAVA_HOME=/home/jdk1.8.0_131
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
执行source /etc/profile立即生效。
3.2.6 Hadoop安装和配置
- 创建用户和用户组。
groupadd hadoop
adduser -g hadoop hadoop
3.2.7 无密码登陆
步骤一: ssh-key-gen在hadoopmaster主机上创建公钥与密钥。需要注意一下,一定要用hadoop用户生成公钥,因为我们是免密钥登录用的是hadoop。
[hadoop@hadoopmaster /]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
fd:63:be:4e:cc:29:0f:d3:64:c4:e1:eb:ed:f1:de:72 hadoop@hadoopmaster
The key's randomart image is:
+--[ RSA 2048]----+
| . |
| o . |
| + |
| . . . |
| S . + |
| O o |
| + @ o |
| O o.oE|
| .=..++|
+-----------------+
步骤二: 保证hadoopmaster登录自已是有效的
cd .ssh
cat ./id_rsa.pub >> ./authorized_keys
步骤三: 将公钥拷贝到其他主机上
scp ~/.ssh/id_rsa.pub hadoop@hadoopslave1:/home/hadoop/
scp ~/.ssh/id_rsa.pub hadoop@hadoopslave2:/home/hadoop/
步骤四 在其他二个节点上做的工作
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 .ssh/authorized_keys #确保权限可用,authorized_keys的权限要是600。
rm ~/id_rsa.pub # 用完就可以删掉了
接着,另外两台服务器也需要如上操作。确保3台服务器之间无密码直接登陆。
3.2.8 HadoopMaster安装和配置
我们把hadoop安装到/hadoop目录下。hadoop的用户和组也是hadoop。
集群/分布式模式需要修改 /hadoop/hadoop-2.8.0/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
- 解压安装
tar -xvf hadoop-2.8.0.tar.gz #解压文件
接着就是配置hadoop的环境变量了,我建议将所有需要的环境变量配置加入到/etc/profile中,这是全局变量。
export HADOOP_INSTALL=/hadoop/hadoop-2.8.0
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib:HADOOP_COMMON_LIB_NATIVE_DIR"
#在启动hadoop的时候经常会出现,找不到JAVA_HOME的问题,这个问题可以通过修改hadoop环境变量来解决,直接写死变量就可以了
vi hadoop-env.sh
export JAVA_HOME=/home/jdk1.8.0_131
- 设置slave
本教程让 hadoopmaster 节点仅作为 NameNode 使用,因此将文件中原来的 localhost 删除,只添加二行内容:hadoopslave1 hadoopslave2。
cd /hadoop/hadoop-2.8.0/etc/hadoop/
vi slaves
将loaclhost删除,填写我们自己设定的两台slave
hadoopslave1
hadoopslave2
- 配置core-site.xml。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopmaster:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/hadoop/hadoop-2.8.0/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
- 配置hdfs-site.xml
dfs.replication 一般设为 3,但我们只有二个 Slave 节点,所以 dfs.replication 的值还是设为 2
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoopmaster:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
- 配置mapred-site.xml
(可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoopmaster:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoopmaster:19888</value>
</property>
</configuration>
- 配置yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoopmaster</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3.2.9 HadoopSlave安装和配置
首先通过sftp把hadoop配置好的hadoop打包,之后转输到Slave节点上,配置好环境变量JDK PATH SSH 基本上与Master是一样的。
在 Master 节点上执行:
tar cvzfz /hadoop/hadoop.master.tar.gz /hadoop/hadoop-2.8.0
scp hadoop.master.tar.gz hadoopslave1:/hadoop #将文件拷贝到slave1和slave2
scp hadoop.master.tar.gz hadoopslave2:/hadoop #将文件拷贝到slave1和slave2
tar -zxvf /hadoop/hadoop.master.tar.gz #解压文件
3.2.10 启动集群
hdfs namenode -format #首次初始化,之后不需要
在Master上执行:
$start-dfs.sh
$start-yarn.sh
$mr-jobhistory-daemon.sh start historyserver
#之后分别在Master与Slave上执行jps,会看到不同的结果.缺少任一进程都表示出错。
#另外还需要在 Master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,
#如果 Live datanodes 不为 0 ,则说明集群启动成功。例如我这边一共有 2 个 Datanodes:
jps
hdfs dfsadmin -report
[hadoop@hadoopmaster sbin]$ jps
6209 ResourceManager
6563 Jps
6491 JobHistoryServer
5868 NameNode
6062 SecondaryNameNode
[hadoop@hadoopslave1 hadoop]$ jps
11368 Jps
11146 DataNode
11243 NodeManager
访问http://192.168.44.131:50070/查看结果。
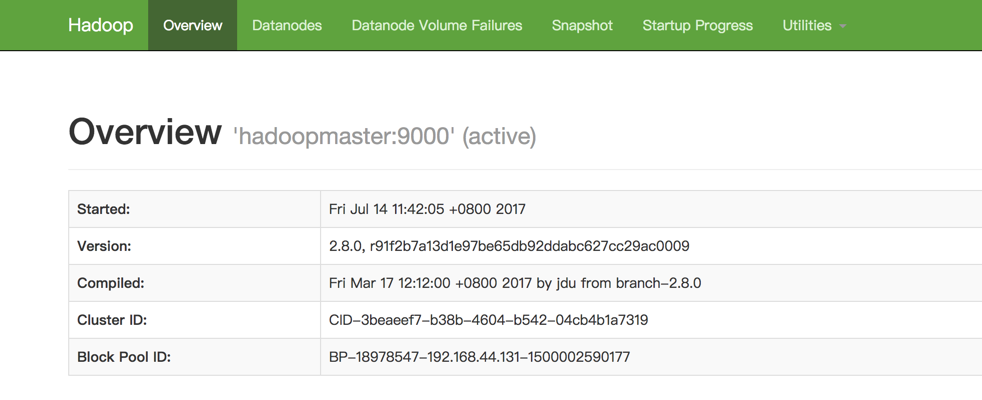
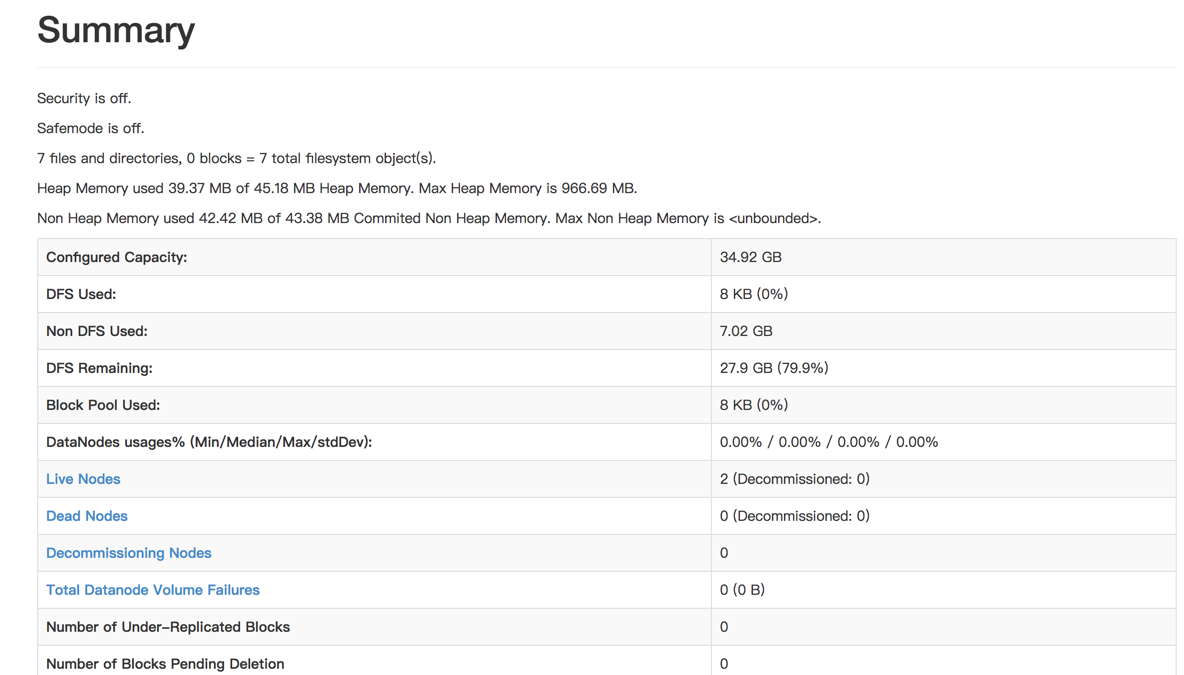
3.2.11 测试Hadoop集群
- 分布式存储
$ hdfs dfs -mkdir -p /user/hadoop
$ hdfs dfs -mkdir input
$ hdfs dfs -put /hadoop/hadoop-2.8.0/etc/hadoop/*.xml input
通过查看 DataNode 的状态(占用大小有改变),输入文件确实复制到了 DataNode 中,如下图所示
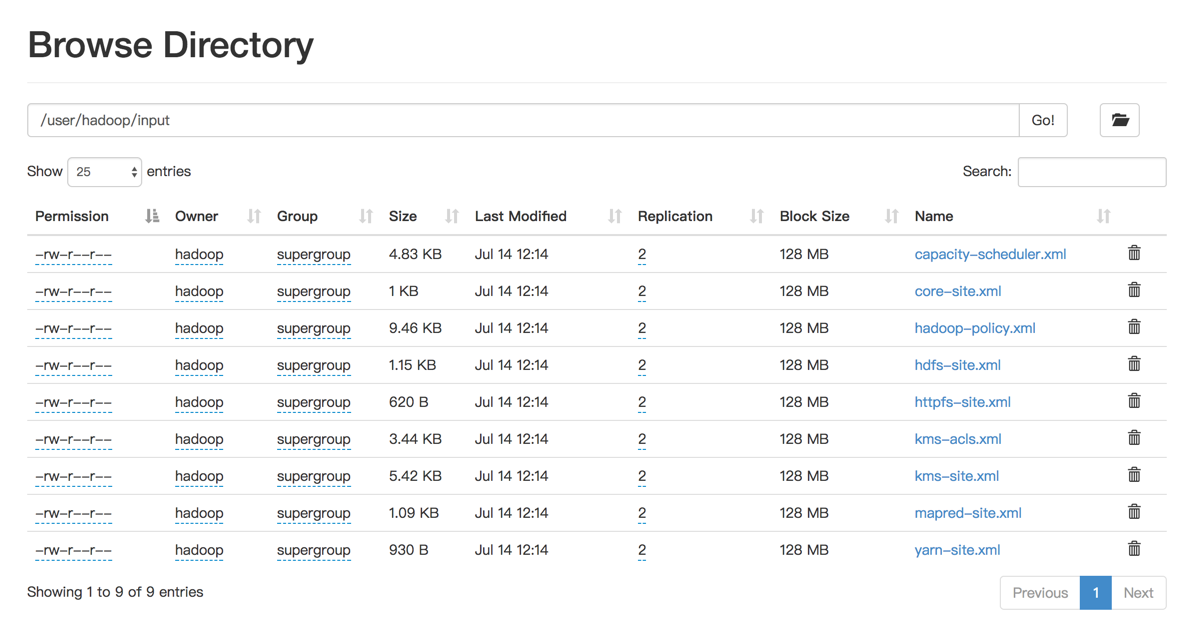 2.分布式计算测试
2.分布式计算测试
hadoop jar /hadoop/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+'
进入地址:http://192.168.44.131:8088/cluster/apps查看任务执行情况。
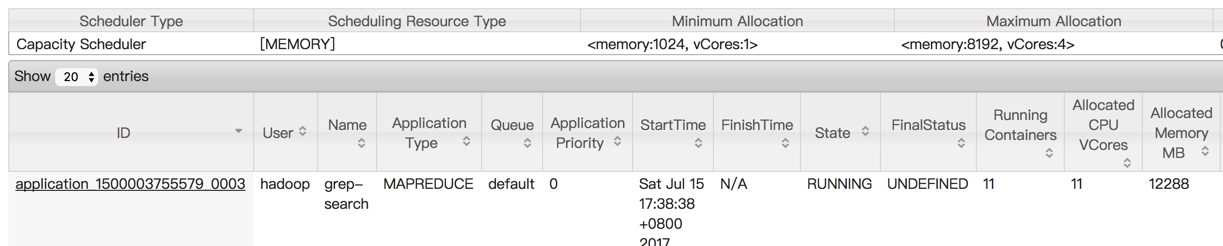
3.2.12 关闭集群
关闭集群
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver