5.8 分区表
分区表实际上是将原来在关系型数据库中的一个大表的数据分开来存储。
在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。
一个典型的案例:每日新增用户。
在关系型数据库中,我们会给用户表添加一个字段register_time,如果要查询某天的新增用户的时候,我们制定regster_time等于某一天。
HIVE采取了另外一种策略,即存储的时候就将每天的数据分开来存,每天的数据存储在不同的位置上,那么在查询的时候,只要需要操作某一天的数据文件即可,不需要查询所有的数据,然后再进行过滤。
- Partition对应于数据库的Partition列的密集索引
- 在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中
分区表的创建:
CREATE TABLE partition_table(id int,name string) PARTITIONED BY(day string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
LOAD DATA LOCAL INPATH '/home/hadoop/partition.txt' INTO TABLE partition_table PARTITION(day='20170801');
LOAD DATA LOCAL INPATH '/home/hadoop/partition.txt' INTO TABLE partition_table PARTITION(day='20170802');
LOAD DATA LOCAL INPATH '/home/hadoop/partition.txt' INTO TABLE partition_table PARTITION(day='20170803');
LOAD DATA LOCAL INPATH '/home/hadoop/partition.txt' INTO TABLE partition_table PARTITION(day='20170804');
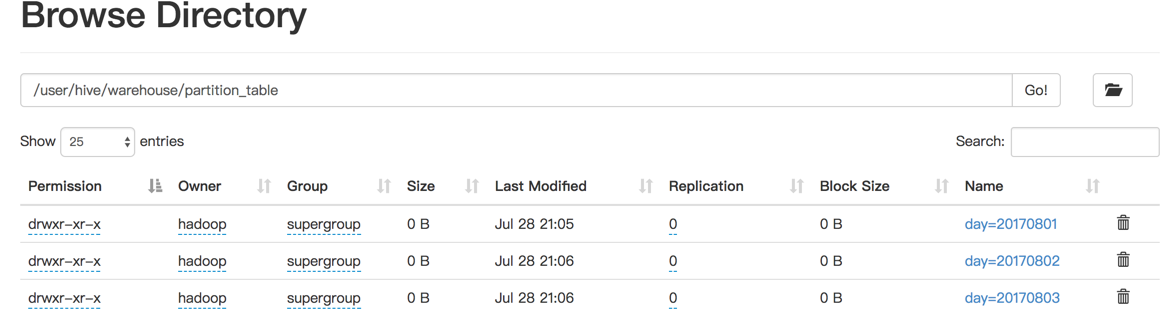
HDFS中的存储方式:
删除分区
hive> alter table partition_table drop partition(day='20170801');
Dropped the partition day=20170801
OK
Time taken: 0.72 seconds
分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。
0: jdbc:hive2://localhost:10000> describe partition_table;
+--------------------------+-----------------------+-----------------------+
| col_name | data_type | comment |
+--------------------------+-----------------------+-----------------------+
| id | int | |
| name | string | |
| day | string | |
| | NULL | NULL |
| # Partition Information | NULL | NULL |
| # col_name | data_type | comment |
| | NULL | NULL |
| day | string | |
+--------------------------+-----------------------+-----------------------+
8 rows selected (0.857 seconds)
查看分区
hive> SHOW PARTITIONS partition_table;
OK
day=20170802
day=20170803
Time taken: 0.291 seconds, Fetched: 2 row(s)