3.4 Hadoop实践
3.4.1 HDFS命令
常用介绍下列常用HDFS命令
本节所有命令,我们都在master虚拟机的“终端”程序中运行。
| 命令 | 说明 |
|---|---|
| hadoop fs -mkdir | 创建HDFS目录 |
| hadoop fs -ls | 列出HDFS目录 |
| hadoop fs -copyFromLocal | 使用-copyFromLocal复制本地(Local)文件到HDFS |
| hadoop fs -put | 使用-put复制本地(local)文件到HDFS |
| hadoop fs -copyToLocal | 使用-copyToLocal将HDFS上的文件复制到本地(Local) |
| hadoop fs -get | 使用-get将HDFS上的文件复制到本地(Local) |
| hadoop fs -cp | 使用HDFS文件 |
| hadoop fs -mv | 删除HDFS文件 |
新建文件夹
$hadoop fs -mkdir /u01
$hadoop fs -mkdir /u01/tmp
#创建多级HDFS目录
查看文件夹权限
$hadoop fs -ls -d /u01/tmp
drwxr-xr-x - hadoop supergroup 0 2017-07-16 02:43 /u01/tmp
上传文件
hadoop fs –put [本地地址] [hadoop目录]
同时也可以上传文件夹
$hadoop fs –put /home/file.txt /user/u01/
#查看文件夹下内容
[hadoop@hadoopmaster home]$ hadoop fs -ls -R /u01/tmp/
-rw-r--r-- 2 hadoop supergroup 1659 2017-07-16 02:57 /u01/tmp/1.txt
查看文件内容
hadoop dfs –cat [文件目录]
$hadoop fs -cat /u01/tmp/1.txt
复制、移动、删除文件
#复制
$hadoop fs -cp /u01/tmp/1.txt /u01/tmp/2.txt
#移动
$hadoop fs -mv /u01/tmp/2.txt /u01/tmp/3.txt
#删除
$hadoop fs -rm /u01/tmp/3.txt
Deleted /u01/tmp/3.txt
创建新的空文件
$hadoop fs -touchz /u01/tmp/5.txt
下载Hadoop上的文件
hadoop fs -get [文件目录] [本地目录]
$hadoop fs -get /u01/tmp/2.txt /home/hadoop
删除文件夹
$hadoop fs –rm -r /u01/tmp
HDFS提供了一些方便选项,比如可以在命令中加上 -R,R代表recursive(递归)
在Hadoop HDFS Web用户界面浏览HDFS
打开地址: http://192.168.44.131:50070/explorer.html#/
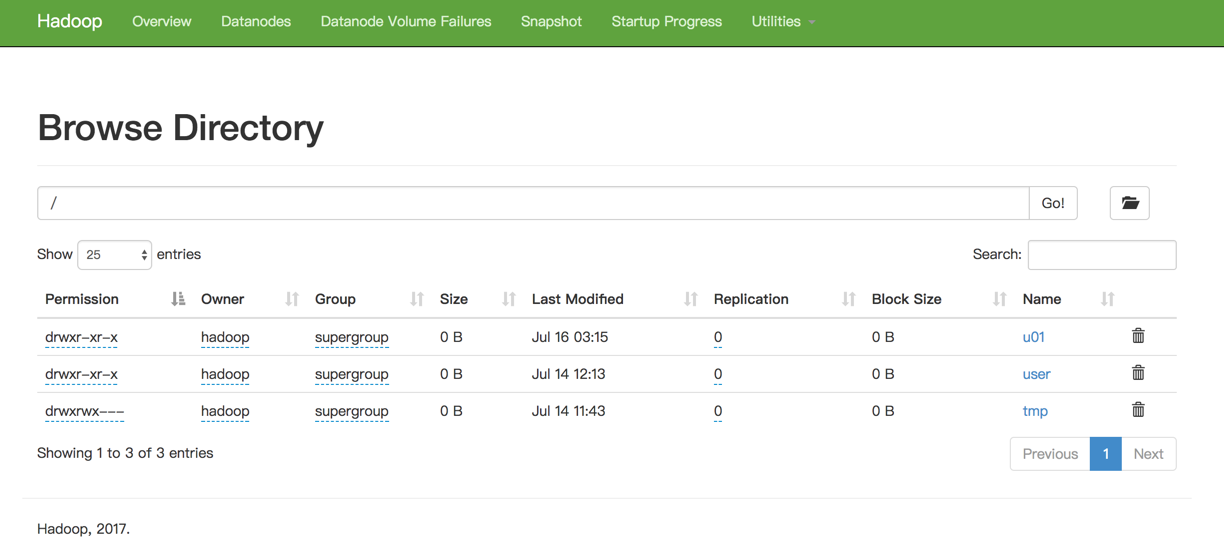
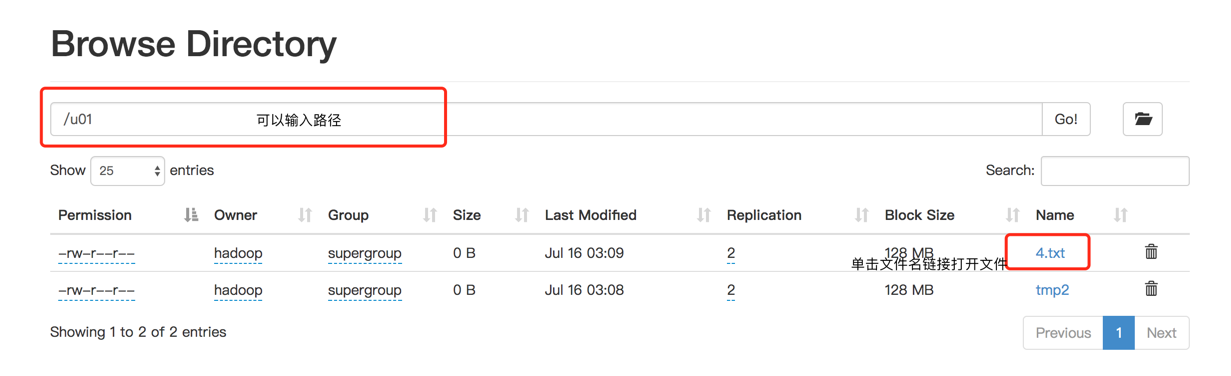 可以输入完整路径直接查看该目录下的文件。
可以输入完整路径直接查看该目录下的文件。
3.4.2 MapReduce
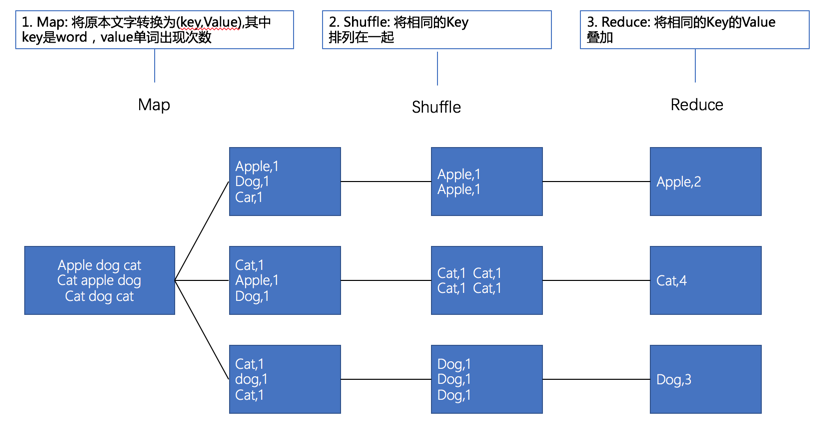
MapReduce是一种程序开发模式,可以使用大量服务器来并行处理。MapReduce,简单地说,Map就是分配工作、Reduce就是将工作整理汇总。
- 首先使用Map将待处理的数据分割成很多的小份数据,由每台服务器分别运行。
- 再通过Reduce程序进行数据合并,最后汇总整理出结果。
本章将用wordCount.java作为范例来介绍MapReduce。
介绍wordCount.java
wordcount用来计算文件中每一个英文单词出现的次数,步骤下图所示:
在Hadoop说明文件中就有Wordcount.java代码,请浏览下列网址:
http://hadoop.apache.org/docs/r2.8.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
步骤如下:
| 顺序 | 开发步骤 | 说明 |
|---|---|---|
| 1 | 编辑wordcount.java | 使用gedit编辑wordcount.java |
| 2 | 编辑wordcount.java | 编译、打包wordcount.java程序 |
| 3 | 创建文本文件 | 使用hadoop目录下LICENSE.txt作为测试文件,并上传文本文件至HDFS |
| 4 | 运行wordcount.java | 在Hadoop环境运行WordCount |
| 5 | 查看运行结果 | 运行会产生输出文件并存储到HDFS中,可使用HDFS命令查看。 |
准备class
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
//Map类
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
//Reduce类
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
编译文件
$export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar #准备环境
$hadoop com.sun.tools.javac.Main WordCount #编译WordCount程序
$jar cf wc.jar WordCount*.class #把WordCount类打包为wc.jar
-rw-rw-r--. 1 hadoop hadoop 3075 Jul 16 05:37 wc.jar
-rw-rw-r--. 1 hadoop hadoop 1491 Jul 16 05:35 WordCount.class
-rw-rw-r--. 1 hadoop hadoop 1739 Jul 16 05:35 WordCount$IntSumReducer.class
-rw-r--r--. 1 root root 2088 Jul 16 05:19 WordCount.java
-rw-rw-r--. 1 hadoop hadoop 1736 Jul 16 05:35 WordCount$TokenizerMapper.class
最后我们生成了wc.jar
创建测试文件
#复制LICENSE.txt
cp /hadoop/hadoop-2.8.0/LICENSE.txt /home/hadoop/
#上传至HDFS目录
hadoop fs -mkdir /u01/wordcount/input
hadoop fs -put /home/hadoop/LIXENSE.txt /u01/wordcount/input
hadoop fs -ls /u01/worcount/input
运行wordcount
$hadoop jar wc.jar WordCount /u01/wordcount/input/LICENSE.txt /u01/wordcount/output
17/07/16 05:55:05 INFO client.RMProxy: Connecting to ResourceManager at hadoopmaster/192.168.44.131:8032
17/07/16 05:55:06 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
17/07/16 05:55:07 INFO input.FileInputFormat: Total input files to process : 1
17/07/16 05:55:07 INFO mapreduce.JobSubmitter: number of splits:1
17/07/16 05:55:07 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1500143031368_0001
17/07/16 05:55:09 INFO impl.YarnClientImpl: Submitted application application_1500143031368_0001
17/07/16 05:55:09 INFO mapreduce.Job: The url to track the job: http://hadoopmaster:8088/proxy/application_1500143031368_0001/
17/07/16 05:55:09 INFO mapreduce.Job: Running job: job_1500143031368_0001
17/07/16 05:55:30 INFO mapreduce.Job: Job job_1500143031368_0001 running in uber mode : false
17/07/16 05:55:30 INFO mapreduce.Job: map 0% reduce 0%
17/07/16 05:55:48 INFO mapreduce.Job: map 100% reduce 0%
17/07/16 05:55:56 INFO mapreduce.Job: map 100% reduce 100%
17/07/16 05:55:57 INFO mapreduce.Job: Job job_1500143031368_0001 completed successfully
17/07/16 05:55:57 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=34111
FILE: Number of bytes written=340407
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=99374
HDFS: Number of bytes written=25627
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=13872
Total time spent by all reduces in occupied slots (ms)=5270
Total time spent by all map tasks (ms)=13872
Total time spent by all reduce tasks (ms)=5270
Total vcore-milliseconds taken by all map tasks=13872
Total vcore-milliseconds taken by all reduce tasks=5270
Total megabyte-milliseconds taken by all map tasks=14204928
Total megabyte-milliseconds taken by all reduce tasks=5396480
Map-Reduce Framework
Map input records=1801
Map output records=14550
Map output bytes=155815
Map output materialized bytes=34111
Input split bytes=121
Combine input records=14550
Combine output records=2194
Reduce input groups=2194
Reduce shuffle bytes=34111
Reduce input records=2194
Reduce output records=2194
Spilled Records=4388
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=280
CPU time spent (ms)=4770
Physical memory (bytes) snapshot=294240256
Virtual memory (bytes) snapshot=4166737920
Total committed heap usage (bytes)=140603392
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=99253
File Output Format Counters
Bytes Written=25627
查看运行结果
执行成功后,结果会输出到/u01/wordcount/output。output目录下会生成两个文件:
- _SUCCESS: 代表程序运行成功
- part-r-00000: 运行结果的文本文件
可以直接查看part-r-00000文件,该文件里会列出每个英文单词出现的次数。
hadoop fs -cat /u01/wordcount/output/part-r-00000|more
Hadoop MapReduce的缺点
MapReduce有以下缺点:
- 程序设计模式不容易使用,而且Hadoop的Map Reduce API太过低级,很难提高开发者效率。
- 有运行效率的问题,Map Reduce需要将中间产生的数据保存到硬盘中,因此会有读写数据延迟的问题。
- 不支持实时处理,它的原始设计就是批处理为主。
3.4.3 搭建Intellij IDEA 环境
使用IDEA创建Maven控工程。
修改pom.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>hk.com.cre</groupId>
<artifactId>hadoop-ml</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.2</version>
</dependency>
</dependencies>
</project>
新建class
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.InputStream;
import java.net.URI;
/**
*
* Created by geguo on 2017/7/27.
*
*/
public class HDFSExample {
public static void main(String[] args){
String uri = "hdfs://192.168.44.131:9000/";
Configuration config = new Configuration();
try {
FileSystem fs = FileSystem.get(URI.create(uri), config);
//列出目录下所有的文件列表
FileStatus[] statuses = fs.listStatus(new Path("/u01/"));
for (FileStatus status : statuses) {
System.out.println(status);
}
// 在hdfs的/u01目录下创建一个文件,并写入一行文本
FSDataOutputStream os = fs.create(new Path("/u01/hadoop.log"));
os.write("开启我的Hadoop之旅".getBytes());
os.flush();
os.close();
}catch (Exception e){
e.printStackTrace();
}
}
}
执行jar
$ hadoop jar hadoop-ml-1.0-SNAPSHOT.jar HDFSExample
FileStatus{path=hdfs://192.168.44.131:9000/u01/ratings.csv; isDirectory=false; length=2438266; replication=2; blocksize=134217728; modification_time=1501124895929; access_time=1501133091132; owner=hadoop; group=supergroup; permission=rw-r--r--; isSymlink=false}
FileStatus{path=hdfs://192.168.44.131:9000/u01/wordcount; isDirectory=true; modification_time=1501133714318; access_time=0; owner=hadoop; group=supergroup; permission=rwxr-xr-x; isSymlink=false}
查看u01/hadoop.log文件
$hadoop fs -cat /u01/hadoop.log
开启我的Hadoop之旅