3.6 HDFS知识自查
为了回顾大家对HDFS的知识掌握程度,利用本节快速对知识进行查漏补缺。
在开始自查之前,我们需要给大家介绍一些内容。
- 数据网站: https://grouplens.org/ 是明尼苏达大学社会计算研究的数据集,里有大量的数据可以供我们在学习的时候使用。
3.6.1 hadoop与云计算之间的关系?
云计算由位于网络上的一组服务器把其计算、存储、数据等资源以服务的形式提供给请求者以完成信息处理任务的方法和过程。针对海量文本数据处理,为实现快速文本处理响应,缩短海量数据为辅助决策提供服务的时间,基于Hadoop云计算平台,建立HDFS分布式文件系统存储海量文本数据集,通过文本词频利用MapReduce原理建立分布式索引,以分布式数据库HBase存储关键词索引,并提供实时检索,实现对海量文本数据的分布式并行处理。所以,Hadoop是云计算的部分构建。
3.6.2 列出hadoop集群启动中的所有进程和进程的作用
a) Namenode 管理集群,记录namenode文件信息;
b) Secondname 可以做备份,对一定范围内的数据做快照;
c) Datanode 存储数据;
d) Jobtarcker 管理任务,分配任务;
e) Tasktracker 执行任务;
3.6.3 MapReduce例子
基于https://grouplens.org 中电影评分的数据
- 将数据保存到HDFS。
- 统计各个评分分别有多少部电影。
首先梳理思路
将文件保存到HDFS比较简单。主要考虑如何对评分进行汇总。
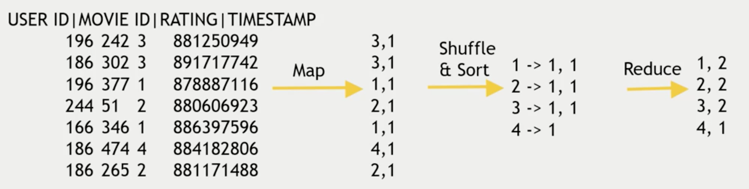
电影的数据主要有,用户ID,电影ID,评分,时间。我们利用这些原始数据进行统计和分析。
整个的过程比较简单:
Map: Map每一行为(评分,1)。
Reduce: 将评分一样的求和。
以下为整个过程:
1)提交文件到HDFS
#下载文件
wget http://files.grouplens.org/datasets/movielens/ml-latest-small.zip
unzip ml-latest-small.zip
#上传文件
hadoop fs -put ratings.csv /u01/
#查看文件
hadoop fs -ls /u01
2)进行统计
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* Created by geguo on 2017/7/28.
*/
public class MlExample {
//Map
public static class csvMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] args = value.toString().split(",");
word.set(args[2]);
context.write(word,one);
}
}
public static class SumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "csv ml count");
job.setJarByClass(MlExample.class);
job.setMapperClass(csvMapper.class);
job.setCombinerClass(SumReducer.class);
job.setReducerClass(SumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
执行
$ hadoop jar hadoop-ml-1.0-SNAPSHOT.jar MlExample /u01/ratings.csv /u01/output
$ hadoop fs -cat /u01/output/part-r-00000
0.5 1101
1.0 3326
1.5 1687
2.0 7271
2.5 4449
3.0 20064
3.5 10538
4.0 28750
4.5 7723
5.0 15095